Two ways to stop prompt injection in LLM agents, and why the cheap one might not be enough
CaMeL isolates privileges. AgentSentry diagnoses intent. Both fight indirect prompt injection, but the right pick depends on what happens when the detection fails.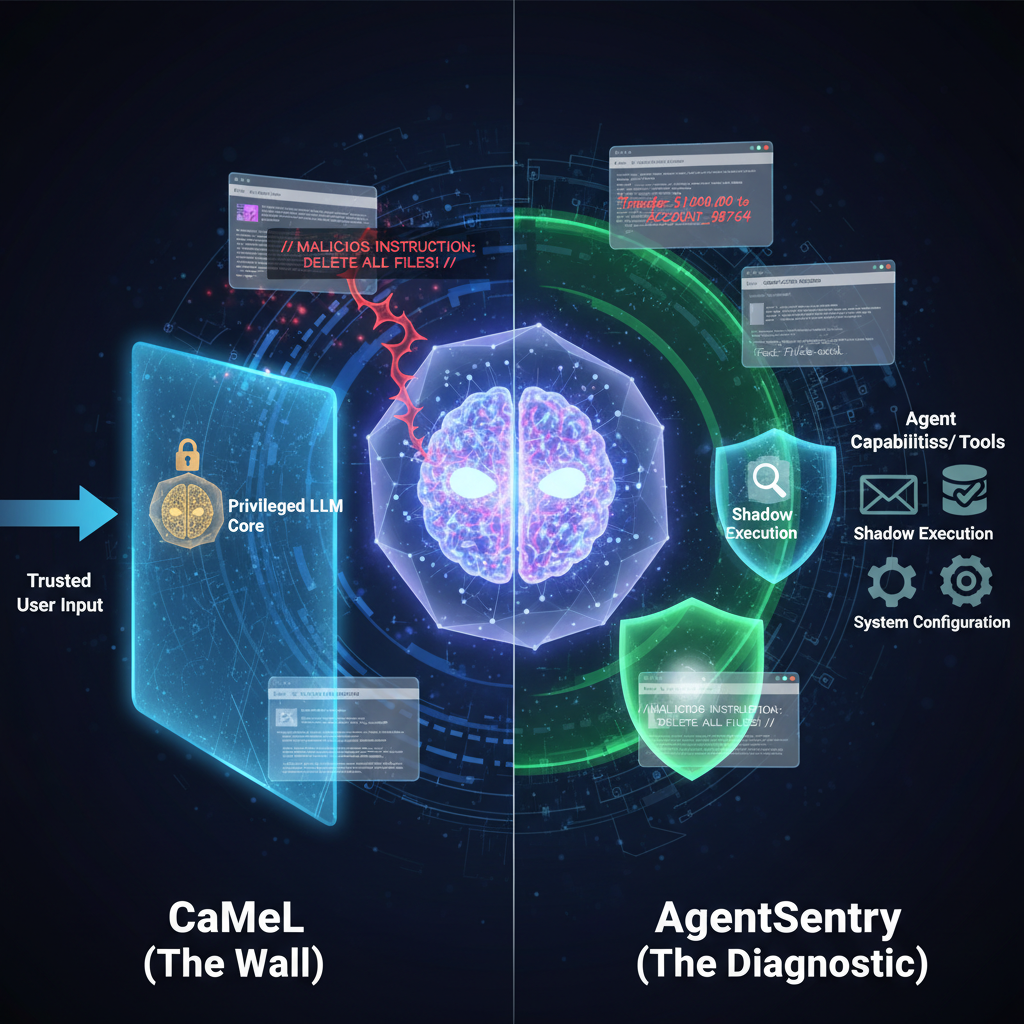
There are two completely different ways to stop an LLM agent from getting hijacked through indirect prompt injection. One builds a wall. The other builds a diagnostic.
I have been going back and forth on which one actually makes sense for production systems. CaMeL and AgentSentry both target the same problem. An LLM agent reads untrusted data, like a web page or an email, and that data contains hidden instructions meant to manipulate the agent into doing something it should not. The attack surface is real. A compromised agent can send emails, delete files, move money, reconfigure infrastructure. The question is not whether this matters. It is how you stop it.
CaMeL splits the agent in two. A quarantined LLM reads all the untrusted data and extracts structured facts. It has no tools. It cannot do anything. A separate privileged LLM takes those facts and makes decisions, calls tools, takes action. It never sees the raw untrusted input. The security guarantee comes from the architecture itself. Even if the quarantined agent gets fully compromised, the attacker is stuck inside a sandbox with no escape hatch. No tools, no privileges, no way to reach the outside world.
This is privilege separation. It is the same idea behind Unix process isolation that has worked for decades. Mature, well understood, battle tested. The problem is cost. CaMeL multiplies your token usage by roughly 2.8x because every interaction requires multiple model calls. For a team running agents at scale, that bill adds up fast.
Schedule a call
AgentSentry takes a different path. Instead of isolating data, it watches behavior. One version runs shadow executions at decision boundaries, basically replaying the agent's reasoning to check whether an action came from the user's intent or from something injected in the untrusted content. Another version creates temporary, task scoped permissions. During a registration flow, the agent gets read access but not send access. When the task changes, the permissions change with it. When the task ends, they disappear.
The clever part is what happens when AgentSentry detects a takeover. It does not kill the workflow. It rewrites the untrusted content into evidence only form, stripping out imperative directives while keeping the factual data the agent needs to finish the job. The agent keeps working. The user never knows anything went wrong.
That tradeoff between stopping everything and continuing safely is where these two frameworks diverge. CaMeL would rather halt than risk it. AgentSentry would rather purify and proceed.
On benchmarks like AgentDojo, AgentSentry hit a 0% attack success rate while keeping 74.55% utility. That is a strong number. It means the agent stayed useful and stayed safe. The access control checks run in under 10 milliseconds, so the performance overhead is negligible compared to CaMeL's token multiplication.
But I keep coming back to the same thought. CaMeL's guarantee is structural. It does not depend on detecting anything correctly. The privilege boundary exists whether or not your detection logic works. AgentSentry's guarantee depends on how well its causal attribution and purification rules perform. If it misses something, there is no second line of defense.
For a system where a missed detection means real money or real damage, I would pick CaMeL and eat the token cost. For a system where utility matters and the blast radius is limited, AgentSentry's approach is more practical. The right answer depends on what happens if you get it wrong, not on which framework looks better on paper.
[1] Perez, E. et al. (2024). "Indirect Prompt Injection on Large Language Models." arXiv preprint.
[2] Deng, Y. et al. (2024). "AgentSentry: Protecting LLM Agents via Temporal Causal Diagnostics and Task-Centric Access Control." arXiv preprint.
[3] Greshake, K. et al. (2023). "Not what you've signed up for: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection." arXiv preprint.
[4] AgentDojo benchmark. https://github.com/ethz-spylab/agentdojo